פלטפורמה ליצירת נתונים סינתטיים עבור מודלים של למידת מכונה
visynth.ai מאפשרת לחברות לייצר תמונות סינתטיות באיכות גבוהה לצורך אימון ואימות של מודלים לראייה ממוחשבת. המערכת נועדה להתמודד עם מחסור בנתונים, לשפר את ביצועי המודלים ולייעל את תהליך העבודה — החל מייבוא מערכי נתונים ועד לאימון המודל.
מטרות עיקריות
הצוות שלנו סייע לבנות את Visynth.ai מאפס, תוך טיפול בפיתוח צד לקוח, לוגיקת צד שרת בפייתון ותשתית DevOps חסרת שרתים על גבי AWS.
לבנות פלטפורמה חזקה וחסרת שרתים מאפס, המסוגלת להתמודד עם מערכי נתונים גדולים, פריסת מודלי בינה מלאכותית ותהליכי עיבוד נתונים.
לאפשר למשתמשים לייבא, לארגן ולסמן מערכי נתונים בצורה אמינה, תוך יצירת קלטים איכותיים לאימון ובדיקת מודלים של למידת מכונה.
לתכנן וליישם יצירת נתונים סינתטיים אוטומטית עם שיפור איטרטיבי ומשוב אנושי בלולאה לצורך שיפור ביצועי המודלים.
אתגר
להבטיח שהפלטפורמה תנתח במדויק מערכי נתונים נכנסים ותייצר תמונות סינתטיות מגוונות ורלוונטיות במיוחד, תוך שמירה על איכות הנתונים ועקביותם.
פתרון
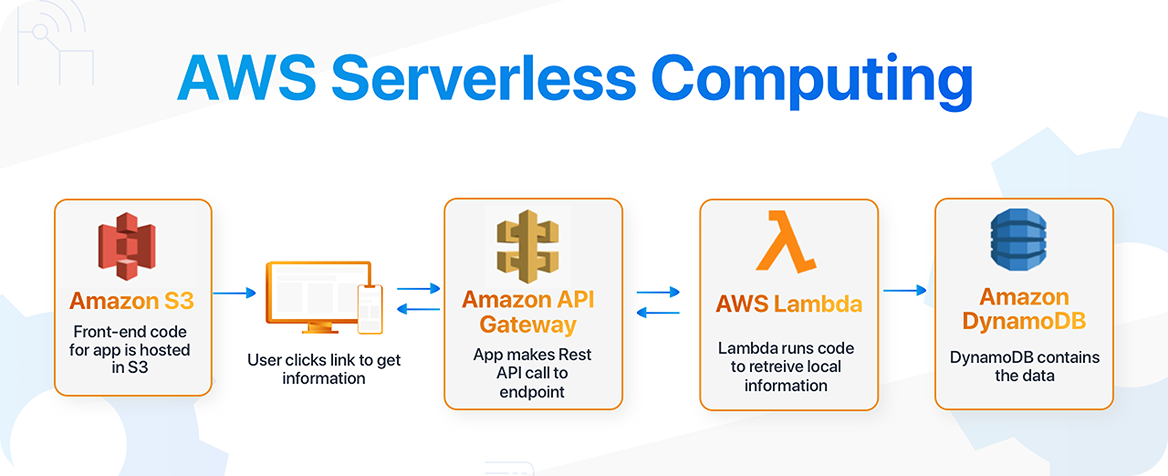
בנינו ארכיטקטורה חסרת שרתים ניתנת להרחבה באמצעות AWS Lambda, SageMaker ופייתון, תוך שילוב כלי צד לקוח מותאמים לסימון ולמשוב.

תנו ל-GenAI לראות את מה שמערכות ראייה מבוססות בינה מלאכותית אחרות מפספסות
עברו מעבר למערכות ראייה מתוסרטות עם GenAI אדפטיבי שמזהה, לומד ופועל — וחושף פגמים, סטיות ובעיות נסתרות שאף מודל מסורתי לא יכול לזהות.

פיצ'רים
מאפשר למשתמשים לסמן ידנית פגמים בתמונות באמצעות פוליגונים, עקומות ותיבות תחימה. מבטיח הכנת נתונים מדויקת לצורך אימון מודלים של למידת מכונה ויצירת תמונות.
מאפשר למשתמשים להגדיר תבניות פגמים ולהגדיר את הצורה, הגודל והווריאציה שלהן. כך מונחית יצירת תמונות סינתטיות ריאליסטיות בהתאם לדרישות ספציפיות של מערך הנתונים.

המשתמשים יכולים לסקור את התמונות שנוצרו ולספק עליהן משוב, ולאחר מכן המערכת יוצרת אותן מחדש באופן איטרטיבי עד שהתוצאות עומדות לשביעות רצונם.
תעשיות






ממערך נתונים ראשוני
לנתונים סינתטיים: שלב אחר שלב
לאחר העלאת התמונות ל-AWS S3, המשתמשים יכולים לבחור את מערך הנתונים המתאים בפלטפורמה.

המשתמשים מסמנים ידנית פגמים או אובייקטים בעלי עניין בתמונות באמצעות פוליגונים, תיבות תחימה או צורות מותאמות אישית. עבור כל מחלקה נוצרות מסכות שחור-לבן, המשמשות מאוחר יותר לאימון מודלים וליצירת נתונים.

הפלטפורמה יוצרת תמונות באופן איטרטיבי על בסיס קונספטים מאושרים. המשתמשים סוקרים מדגם (לדוגמה, 50 תמונות) ומספקים משוב על האיכות והדיוק.

המשוב מעובד אוטומטית על ידי אלגוריתמי הפלטפורמה. נוצרות גרסאות מרובות של הקונספט, שכל אחת משתפרת בהתאם לקלט המשתמש, עד שהלקוח מאשר את התוצאות.

לאחר האישור, הלקוח יוצר אצווה גדולה של תמונות סינתטיות (מאות או אלפים). תמונות אלו מוכנות לייצוא ויכולות לשמש לאימון מודלים של למידת מכונה.

פרויקטים
 מערכי נתונים
מערכי נתונים
המשתמש מתחיל בהגדרת פרויקט חדש, תוך ציון שם ובחירת מקור מערך הנתונים. שלב זה מאתחל את סביבת העבודה ומכין את הפלטפורמה לטיפול בנתוני תמונה לעיבוד נוסף.


ייבוא מערך נתונים
המשתמשים מייבאים תמונות באמצעות חיבור לאחסון קיים, כגון דליי AWS S3, כך שהפלטפורמה תוכל לנתח את מערך הנתונים ולחלץ מידע מרכזי כמו מספר התמונות, המחלקות והמטא-נתונים.

כיצד להוסיף מחלקות
המשתמש בוחר תמונה מתוך מערך הנתונים שיובא ופותח את כלי הסימון. הוא משתמש בפוליגונים כדי לסמן את אזורי הפגמים.
המשתמשים נותנים שם למחלקה החדשה ומשתמשים בפוליגונים כדי לסמן את האזורים הרלוונטיים של הפגם בתמונה. ניתן לשלב מספר פוליגונים כדי להדגיש במדויק פגמים מורכבים או אובייקטים בעלי עניין.
לאחר שהמחלקה הוגדרה וסומנה, הסימון נשמר ומוחל על מערך הנתונים, מה שהופך אותו למוכן ליצירת תמונות סינתטיות.
יצירת קונספט
בחרו תת-קבוצה של תמונות ממערך הנתונים שיובא וספקו הנחיה או תיאור של הפגם שברצונכם למודל.
הוציאו תמונות עם סימונים באיכות נמוכה או פגמים לא רלוונטיים כדי לשמור על איכות הנתונים.
קבעו את הגדרות הצורה של הקונספט — בחרו פוליגונים, עיגולים או מלבנים והתאימו את הגודל והווריאציה.
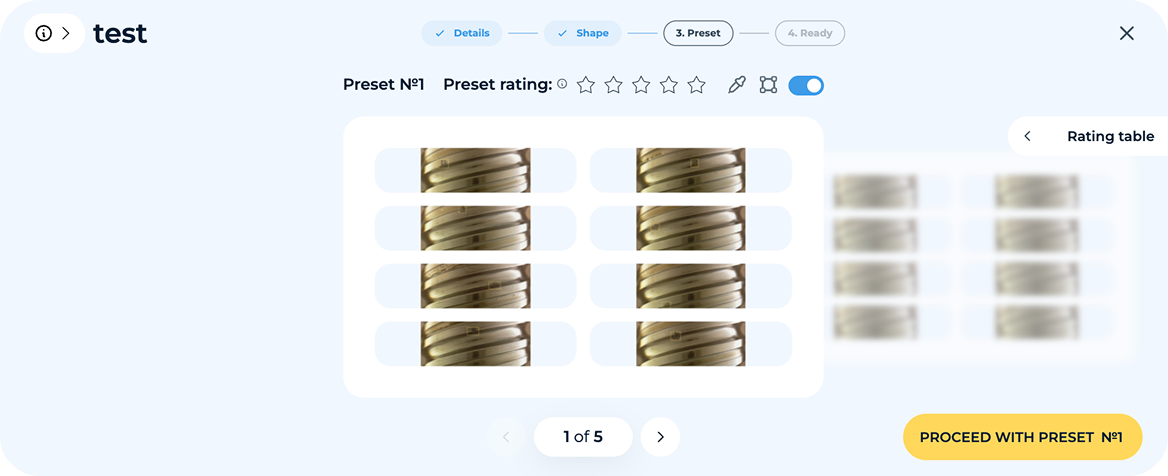
לאחר יצירת הקונספט, צרו תמונות תצוגה מקדימה כדי לסקור ולספק משוב.

לולאת שיפור מבוססת בינה מלאכותית
לאחר יצירת הסט הראשון של תמונות סינתטיות, המשתמשים סוקרים מדגם ומספקים משוב על האיכות, הדיוק והריאליזם. הפלטפורמה מעבדת את המשוב באופן אוטומטי, ומתאימה צורות, וריאציות ומיקומי פגמים כדי לשפר דורות עתידיים. תהליך איטרטיבי זה נמשך עד לשביעות רצון המשתמש.



יצירת אצווה
לאחר שהקונספט עבר שיפור והמשתמש מרוצה מהתוצאות, ניתן ליצור אצווה מלאה של תמונות סינתטיות. האצווה יכולה לכלול מאות ואף אלפי תמונות, כולן מבוססות על הקונספט המאושר ועל וריאציות הפגמים.

המשתמשים יכולים לאמן מודלים של למידת מכונה באמצעות מערכי נתונים ואצוות שהוכנו בשלבים הקודמים. ניתן להשתמש הן בתמונות מסומנות והן בתמונות לא מסומנות, יחד עם אצוות סינתטיות, כנתוני קלט.
כיצד לאמן את המודל?

המשתמשים בוחרים מערכי נתונים ו/או אצוות סינתטיות להזנה למודל.
המשתמשים בוחרים אצוות, בוחרים תמונות ספציפיות לאימון, מגדירים מחלקות, בוחרים מערך נתונים ומגדירים אימות ועוד.
לאחר שכל הפרמטרים הוגדרו, המודל מוכן לאימון. בלחיצה על כפתור ההתחלה, התהליך מתחיל.
עם סיום האימון, המשתמשים יכולים לסקור מדדים ולהעריך עד כמה המודל מבצע זיהוי פגמים בצורה טובה.
תוצאות סופיות
הודות לזרימת עבודה אינטואיטיבית ולכלי סימון נוח, המשתמשים יכולים לסמן פגמים בקלות, מה שהופך את הכנת מערכי הנתונים למהירה, מדויקת וללא מאמץ — גם עבור תמונות מורכבות.

עשינו שימוש ב-AWS Lambda לעיבוד חסר שרתים וב-SageMaker לפריסת מודלים של בינה מלאכותית. מערך זה סיפק תשתית ניתנת להרחבה, יעילה ודורשת תחזוקה מינימלית לאימון מודלים וליצירת תמונות סינתטיות.
יישמנו ארכיטקטורת AWS חסרת שרתים במלואה, עם אוטומציה של סקיילינג, ניטור וטיפול מאובטח בנתונים. כך הבטחנו ביצועים אמינים גם עם מערכי נתונים גדולים ויצירת אצוות בהיקף גבוה.