Plattform zur Generierung synthetischer Daten für Machine-Learning-Modelle
visynth.ai ermöglicht Unternehmen die Erstellung hochwertiger synthetischer Bilder zur Trainings- und Validierungszwecken von Computer-Vision-Modellen. Die Plattform wurde entwickelt, um Datenknappheit zu überwinden, die Modellleistung zu verbessern und den gesamten Workflow von der Datensatz-Integration bis zum Modelltraining zu optimieren.
Hauptziele
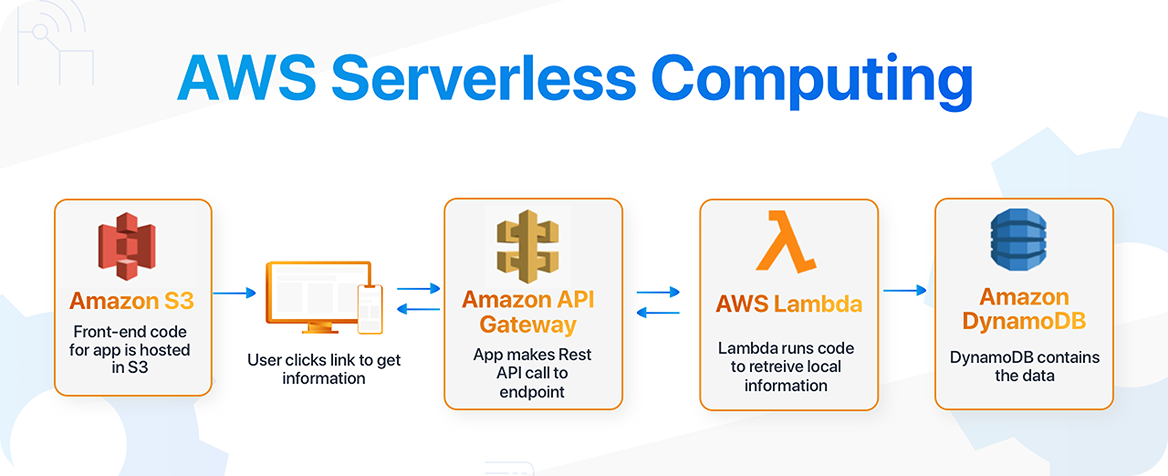
Unser Team entwickelte Visynth.ai von Grund auf neu — inklusive Frontend-Entwicklung, Backend-Logik in Python sowie einer serverlosen DevOps-Infrastruktur auf AWS.
Aufbau einer robusten, serverlosen Plattform, die große Datensätze, KI-Modellbereitstellung und komplexe Datenverarbeitungs-Workflows zuverlässig verarbeitet.
Ermöglicht den Import, die Organisation und präzise Annotation von Datensätzen, um hochwertige Trainings- und Testdaten für ML-Modelle bereitzustellen.
Konzeption und Implementierung einer automatisierten synthetischen Datengenerierung mit iterativer Verfeinerung und Human-in-the-Loop-Feedback zur Verbesserung der Modellleistung.
Herausforderung
Sicherstellen, dass die Plattform eingehende Datensätze präzise analysiert, hochrelevante und vielfältige synthetische Bilder erzeugt und gleichzeitig Datenqualität sowie Konsistenz gewährleistet.
Lösung
Entwicklung einer skalierbaren serverlosen Architektur mit AWS Lambda, SageMaker und Python, ergänzt durch maßgeschneiderte Frontend-Tools für Annotation und Feedback.

GenAI erkennt, was andere KI-Vision-Systeme übersehen
Gehen Sie über starre Vision-Systeme hinaus und setzen Sie auf adaptive GenAI, die Defekte, Abweichungen und versteckte Probleme erkennt, lernt und eigenständig darauf reagiert — weit über die Möglichkeiten klassischer Modelle hinaus.

Funktionen
Ermöglicht die manuelle Markierung von Defekten mittels Polygonen, Kurven und Bounding Boxes. Sorgt für eine präzise Datenaufbereitung für das Training von ML-Modellen und die Bildgenerierung.
Benutzer können Defektvorlagen definieren und deren Form, Größe sowie Variationen konfigurieren. Diese Parameter steuern die Generierung realistischer synthetischer Bilder basierend auf projektspezifischen Anforderungen.

Nutzer können generierte Bilder prüfen und Feedback geben. Das System regeneriert die Daten iterativ, bis die Ergebnisse den Erwartungen entsprechen.
Branchen






Vom initialen Datensatz
zu synthetischen Daten: Schritt für Schritt
Nach dem Hochladen der Bilder in AWS S3 können Nutzer den entsprechenden Datensatz innerhalb der Plattform auswählen.

Nutzer markieren Defekte oder relevante Objekte manuell mithilfe von Polygonen, Bounding Boxes oder benutzerdefinierten Formen. Für jede Klasse werden Schwarz-Weiß-Masken erzeugt, die später für das Modelltraining und die Datengenerierung verwendet werden.

Die Plattform erzeugt iterativ Bilder auf Basis freigegebener Konzepte. Nutzer prüfen eine Stichprobe (z. B. 50 Bilder) und geben Feedback zu Qualität und Genauigkeit.

Das Feedback wird automatisch von den Algorithmen der Plattform verarbeitet. Es werden mehrere Varianten des Konzepts erzeugt, die sich anhand der Nutzerrückmeldungen kontinuierlich verbessern, bis der Kunde die Ergebnisse freigibt.

Nach der Freigabe erzeugt der Kunde große Batches synthetischer Bilder (Hunderte oder Tausende). Diese Bilder sind sofort exportierbar und für das Training von ML-Modellen geeignet.

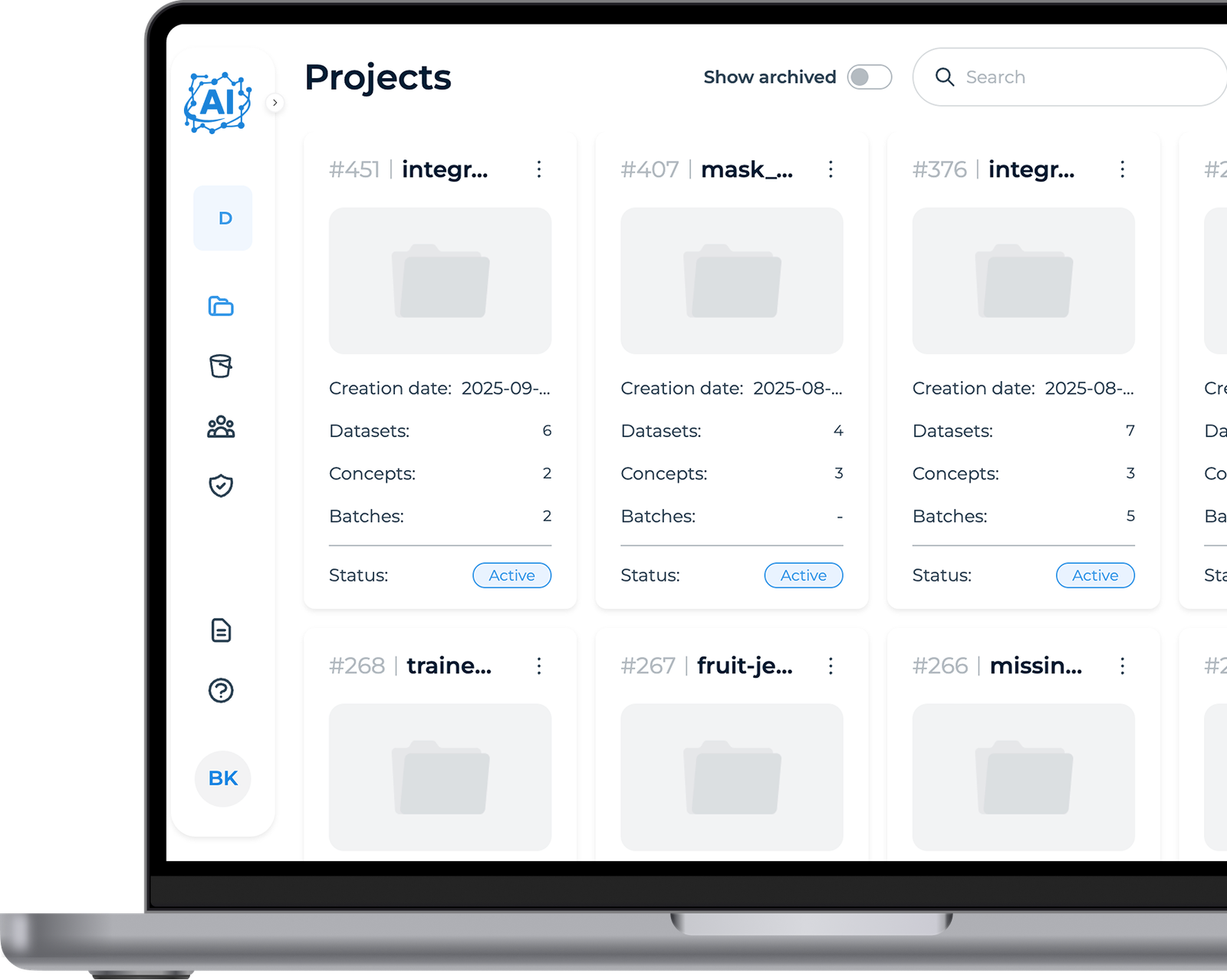
Projekte
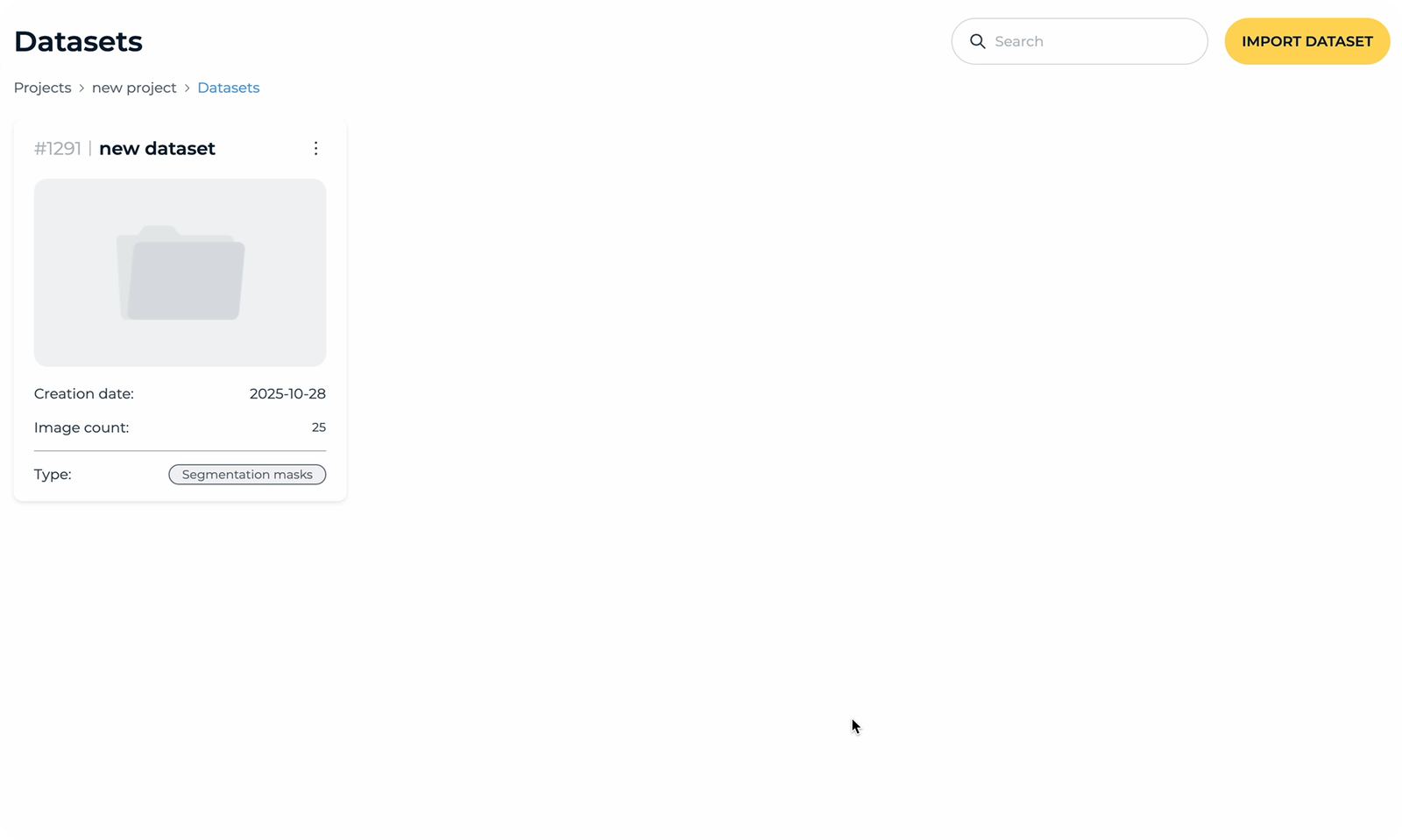
 Datensätze
Datensätze
Der Nutzer beginnt mit der Einrichtung eines neuen Projekts, vergibt einen Namen und wählt die Quelle des Datensatzes aus. Dieser Schritt initialisiert den Arbeitsbereich und bereitet die Plattform auf die Verarbeitung der Bilddaten vor.


Datensatz importieren
Nutzer importieren Bilder durch die Anbindung bestehender Speicherlösungen wie AWS-S3-Buckets. Die Plattform analysiert den Datensatz und extrahiert wichtige Informationen wie Bildanzahl, Klassen und Metadaten.

Klassen hinzufügen
Der Nutzer wählt ein Bild aus dem importierten Datensatz und öffnet das Annotationstool, um Defektbereiche mit Polygonen zu markieren.
Nutzer vergeben einen Namen für die neue Klasse und markieren relevante Defektbereiche im Bild. Mehrere Polygone können kombiniert werden, um komplexe Defekte oder Objekte präzise hervorzuheben.
Nach dem Speichern wird die Annotation auf den Datensatz angewendet und dieser für die Generierung synthetischer Bilder vorbereitet.
Konzept-Erstellung
Auswahl einer Teilmenge von Bildern aus dem importierten Datensatz sowie Beschreibung des zu modellierenden Defekts mittels Prompt oder Text.
Ausschluss von Bildern mit fehlerhaften Annotationen oder irrelevanten Defekten zur Sicherstellung der Datenqualität.
Definition der Formparameter des Konzepts, einschließlich Polygonen, Kreisen oder Rechtecken, sowie Anpassung von Größe und Variation.
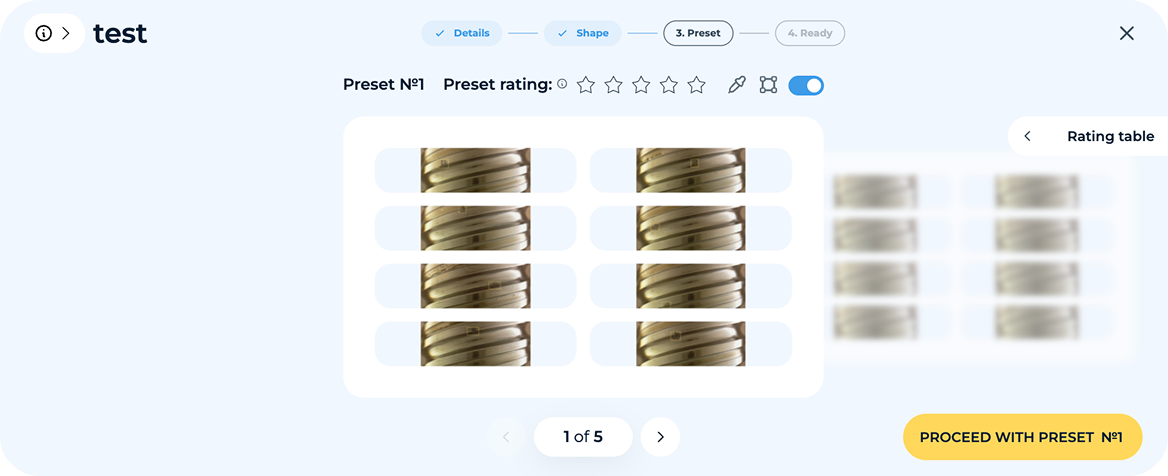
Nach der Erstellung des Konzepts werden Vorschaubilder generiert, die geprüft und kommentiert werden können.

KI-Optimierungsschleife
Nachdem der erste Satz synthetischer Bilder generiert wurde, prüfen die Nutzer eine Stichprobe und geben Feedback zu Qualität, Genauigkeit und Realismus. Die Plattform verarbeitet dieses Feedback automatisch, passt Formen, Variationen und die Platzierung von Defekten an und verbessert so nachfolgende Generationen. Dieser iterative Prozess wird fortgesetzt, bis der Nutzer mit dem Ergebnis zufrieden ist.



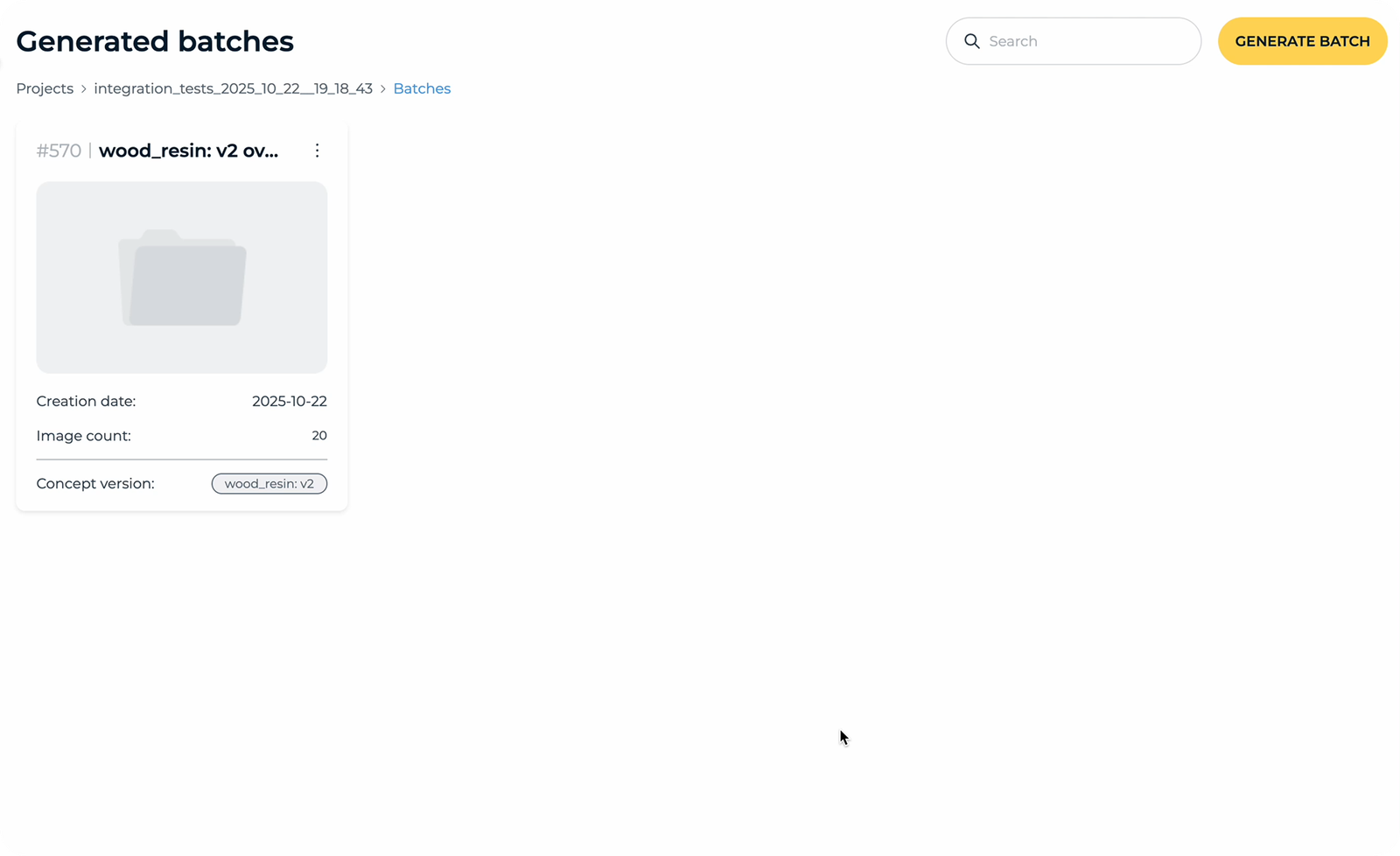
Batch generieren
Nachdem das Konzept verfeinert wurde und der Nutzer mit den Ergebnissen zufrieden ist, kann ein vollständiger Batch synthetischer Bilder erzeugt werden. Der Batch kann Hunderte oder sogar Tausende von Bildern umfassen, die alle auf dem freigegebenen Konzept und den definierten Defektvariationen basieren.

Nutzer können ML-Modelle mit Datensätzen und Batches trainieren, die in den vorherigen Schritten vorbereitet wurden. Sowohl annotierte als auch nicht annotierte Bilder sowie synthetische Batches können als Eingabedaten verwendet werden.
Wie wird das Modell trainiert?

Nutzer wählen Datensätze und/oder synthetische Batches aus, die dem Modell als Trainingsdaten zugeführt werden.
Nutzer wählen Batches aus, bestimmen konkrete Bilder für das Training, definieren Klassen, wählen einen Datensatz und richten Validierungsschritte ein.
Sobald alle Parameter festgelegt sind, ist das Modell bereit für das Training. Nach dem Klick auf den Start-Button beginnt der Trainingsprozess.
Nach Abschluss des Trainings können Nutzer Kennzahlen einsehen und beurteilen, wie zuverlässig das Modell Defekte erkennt.
Ergebnisse
Dank des intuitiven Workflows und des benutzerfreundlichen Annotationstools können Nutzer Defekte einfach markieren. Die Datensatzvorbereitung wird dadurch schnell, präzise und auch bei komplexen Bildern effizient.

Wir setzten AWS Lambda für serverlose Verarbeitung und SageMaker für die Bereitstellung von KI-Modellen ein. Diese Architektur bietet eine skalierbare, effiziente und wartungsarme Infrastruktur für Modelltraining und die Generierung synthetischer Bilder.
Wir implementierten eine vollständig serverlose AWS-Architektur mit automatischer Skalierung, Monitoring und sicherer Datenverarbeitung. Dadurch wurde eine zuverlässige Performance auch bei großen Datensätzen und hoher Batch-Auslastung gewährleistet.